
Hi,
With John O’Leary and Yves Atchadé , we have just arXived our work on removing the bias of MCMC estimators. Here I’ll explain what this bias is about, and the benefits of removing it.
What bias?
An MCMC algorithm defines a Markov chain 

![\frac{1}{m} \sum_{t=1}^m X_t \to \mathbb{E}_\pi[X]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7Bm%7D+%5Csum_%7Bt%3D1%7D%5Em+X_t+%5Cto+%5Cmathbb%7BE%7D_%5Cpi%5BX%5D&bg=FFFFFF&fg=181818&s=0&c=20201002)
as 

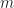

It is common to discard some initial iterations as “burn-in”, in order to mitigate that bias, which is particularly problematic for parallel computations. Indeed you might be able to run many chains in parallel for the price of one, but each chain has to converge to 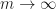
How to remove the bias?
Instead of running one chain, let’s run two chains, 

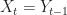


just adding infinitely many zeros. By taking the expectation, swapping limit and expectation and using a telescoping sum argument (the proper justification being in the paper, Section 3), we get that the expectation of the above sum is
![\mathbb{E}[X_{0}] + \sum_{t=1}^\infty (\mathbb{E}[X_{t}] -\mathbb{E}[Y_{t-1}]) = \lim_{t\to\infty}\mathbb{E}[X_{t}] =\mathbb{E}_\pi[X].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7B0%7D%5D+%2B+%5Csum_%7Bt%3D1%7D%5E%5Cinfty+%28%5Cmathbb%7BE%7D%5BX_%7Bt%7D%5D+-%5Cmathbb%7BE%7D%5BY_%7Bt-1%7D%5D%29+%3D+%5Clim_%7Bt%5Cto%5Cinfty%7D%5Cmathbb%7BE%7D%5BX_%7Bt%7D%5D+%3D%5Cmathbb%7BE%7D_%5Cpi%5BX%5D.&bg=FFFFFF&fg=181818&s=0&c=20201002)
This is hugely inspired by Glynn & Rhee (2014), and I had described similar ideas in the setting of smoothing in an earlier post. The contribution of the new arXiv report is to bring this construction to generic MCMC algorithms.
In the diagram above, the two chains meet at time 
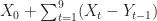
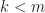
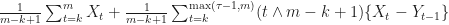
and we give heuristics to choose 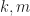
How to construct coupled chains?
We can make Gibbs and Metropolis-Hastings chains meet, as required by the above construction and as described in the paper (Section 4). This means that we can apply the method to a wide variety of settings. In the paper (Sections 5 and 6), we provide applications to hierarchical models, logistic regressions, and the Bayesian Lasso. We also use the method to approximate the “cut” distribution, which arises in Bayesian inference for misspecified models and on which I’ll blog in details soon.
If you use some more fancy MCMC methods, you can either design your custom couplings, or you can interweave your kernel with MH steps in order to create an appropriate coupling without altering much of the marginal mixing of the chains.
What’s the point of unbiased MCMC estimators?
Thanks to the lack of bias, we can compute 

Another advantage of the proposed framework is that confidence intervals can easily be constructed for averages of i.i.d. estimators, using the simple Central Limit Theorem. This is again justified as

8 thoughts on “Unbiased MCMC with couplings”