
Hi,
With Stephane Shao, Jie Ding and Vahid Tarokh we have just arXived a tech report entitled “Bayesian model comparison with the Hyvärinen score: computation and consistency“. Here I’ll explain the context, that is, scoring rules and Hyvärinen scores (originating in Hyvärinen’s score matching approach to inference), and then what we actually do in the paper.
Let’s start with scoring rules. These are loss functions for the task of predicting a variable 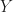



![\mathbb{E}[S(Y,p(dy))]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BS%28Y%2Cp%28dy%29%29%5D&bg=FFFFFF&fg=181818&s=0&c=20201002)

We can interpret Bayes factors in terms of logarithmic scoring rules (as in Chapter 6 of Bernardo & Smith). Indeed, the logarithm of the Bayes factor between model 


In this sense, the Bayes factor compares the predictive performance of models. Decomposing these marginal likelihoods into conditionals and assuming that 
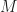

(with a convention for 

So what’s not to like? Prior specification affects the evidence, which is completely fine per se. What’s concerning is the extent of the impact of the prior. Seemingly innocent changes of prior distributions can have drastic effects on the evidence and thus on Bayes factors. This is the case in the simplest example of a Normal location model: 




Conversely, this is a reason to seek alternatives to the evidence as a model comparison criterion, see for instance intrinsic Bayes factors, fractional Bayes factors, or the mixture approach of Kamary et al. Our work follows Dawid & Musio (2015) who propose to change the scoring rule. Instead of the logarithmic scoring rule, they advocate the Hyvärinen scoring rule, which leads to replacing 

This barbaric expression involves derivatives of the log-density of predictive distributions, instead of log-densities. It can then be checked in the Normal location model that the score is well-defined even in the limit
In the paper, we show how sequential Monte Carlo samplers can approximate this scoring rule, for a wide range of models including nonlinear state space models. We also show the consistency of this scoring rule for model selection, as the number of observations goes to infinity; our proof relies on strong regularity assumptions, but the numerical experiments indicate that the results hold under weaker conditions. Finally we investigate an example of population growth model applied to kangaroos, and a Lévy-driven stochastic volatility model which we use to illustrate the consistency result. Both of these cases feature intractable likelihoods approximated by particle filters within an SMC^2 algorithm.
The code producing the figures of the paper is available on Github: https://github.com/pierrejacob/bayeshscore

3 thoughts on “Bayesian model comparison with vague or improper priors”