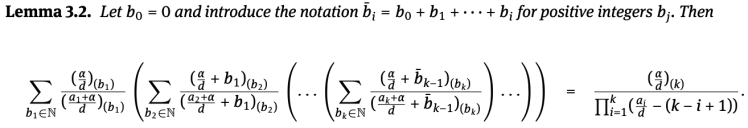
At the dawn of 2020, in case anyone in the stat/ML community is not aware yet of Francis Bach’s blog started last year: this is a great place to learn about general tricks in machine learning explained with easy words. This month’s post The sum of a geometric series is all you need! shows how ubiquitous geometric series are in stochastic gradient descent, among others. In this post, I describe just another situation where the sum of a geometric series can be useful in statistics.
Turning a sum of expectations into a single expectation
I also found the sum of geometric series useful for turning a sum of expectations into a single expectation, by the linearity of expectation. More specifically, for a random variable 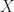
![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=FFFFFF&fg=181818&s=0&c=20201002)
![\sum_{k=1}^\infty \mathbb{E}[X^k] = \mathbb{E}\big[\sum_{k=1}^\infty X^k\big] = \mathbb{E}\big[\frac{X}{1-X}\big],](https://s0.wp.com/latex.php?latex=%5Csum_%7Bk%3D1%7D%5E%5Cinfty+%5Cmathbb%7BE%7D%5BX%5Ek%5D+%3D+%5Cmathbb%7BE%7D%5Cbig%5B%5Csum_%7Bk%3D1%7D%5E%5Cinfty+X%5Ek%5Cbig%5D+%3D+%5Cmathbb%7BE%7D%5Cbig%5B%5Cfrac%7BX%7D%7B1-X%7D%5Cbig%5D%2C&bg=FFFFFF&fg=181818&s=0&c=20201002)
where the sum can be infinite. Let us specify this with Beta variables: let 


![\mathbb{E}[X^k] = \frac{(\alpha)_k}{(\alpha+\beta)_k}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5Ek%5D+%3D+%5Cfrac%7B%28%5Calpha%29_k%7D%7B%28%5Calpha%2B%5Cbeta%29_k%7D&bg=FFFFFF&fg=181818&s=0&c=20201002)
where 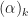

On the one hand, the sum 
![\mathbb{E}\big[\frac{X}{1-X}\big]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cbig%5B%5Cfrac%7BX%7D%7B1-X%7D%5Cbig%5D&bg=FFFFFF&fg=181818&s=0&c=20201002)
![\mathbb{E}\big[X^a(1-X)^b\big] = \frac{B(\alpha+a,\beta+b)}{B(\alpha,\beta)}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cbig%5BX%5Ea%281-X%29%5Eb%5Cbig%5D+%3D+%5Cfrac%7BB%28%5Calpha%2Ba%2C%5Cbeta%2Bb%29%7D%7BB%28%5Calpha%2C%5Cbeta%29%7D&bg=FFFFFF&fg=181818&s=0&c=20201002)
for any 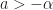
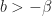
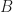
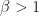
![\sum_{k=1}^\infty \frac{(\alpha)_k}{(\alpha+\beta)_k} = \mathbb{E}\big[\frac{X}{1-X}\big] = \frac{B(\alpha+1, \beta-1)}{B(\alpha,\beta)}= \frac{\Gamma(\alpha+1)\Gamma(\beta)}{\Gamma(\alpha)\Gamma(\beta-1)}= \frac{\alpha}{\beta-1},](https://s0.wp.com/latex.php?latex=%5Csum_%7Bk%3D1%7D%5E%5Cinfty+%5Cfrac%7B%28%5Calpha%29_k%7D%7B%28%5Calpha%2B%5Cbeta%29_k%7D+%3D+%5Cmathbb%7BE%7D%5Cbig%5B%5Cfrac%7BX%7D%7B1-X%7D%5Cbig%5D+%3D+%5Cfrac%7BB%28%5Calpha%2B1%2C+%5Cbeta-1%29%7D%7BB%28%5Calpha%2C%5Cbeta%29%7D%3D+%5Cfrac%7B%5CGamma%28%5Calpha%2B1%29%5CGamma%28%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta-1%29%7D%3D+%5Cfrac%7B%5Calpha%7D%7B%5Cbeta-1%7D%2C&bg=FFFFFF&fg=181818&s=0&c=20201002)
which wasn’t trivial to me a priori.
Where I’ve used this trick
In a joint work with Caroline Lawless, who was an intern at Inria Grenoble Rhône-Alpes in 2018 (now Ph.D. candidate between Oxford and Paris-Dauphine), we have proposed a simple proof of Pitman-Yor’s Chinese restaurant process from its stick-breaking representation, thus generalizing a recent proof for the Dirichlet process by Jeff Miller. One of the technical lemmas there was the one provided in the top picture, that we proved by (backward) induction with the identity obtained in the above section.
By the way, the stick-breaking is a distribution over the infinite simplex, i.e. a specific way to randomly break a stick of unit length into infinitely many pieces, 



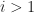
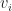

Thanks for reading, and happy 2020 to all!
Julyan
