Long time no see, Statisfaction!
I’m glad to write about my habilitation entitled Bayesian statistical learning and applications I defended yesterday at Inria Grenoble. This Habilitation à Diriger des Recherches (HDR) is the highest degree issued through a university examination in France. If I am to believe official texts, the HDR recognizes a candidate’s “high scientific level, the originality of approach in a field of science, ability to master a research strategy in a sufficiently broad scientific or technological field and ability to supervise young researchers”. No less! In French academia, HDR is a necessary condition for supervising a Ph.D., being a reviewer for a Ph.D., and applying to prof positions. Part of the process consists of writing a manuscript summarizing the research done since the Ph.D. Mine is organized in three parts:
Chapter 1. Bayesian Nonparametric Mixture Modeling. This chapter is devoted to mixture models that are central to Bayesian nonparametrics. It focusses on BNP mixture models for (i) survival analysis, (ii) image segmentation and (ii) ecotoxicological applications.
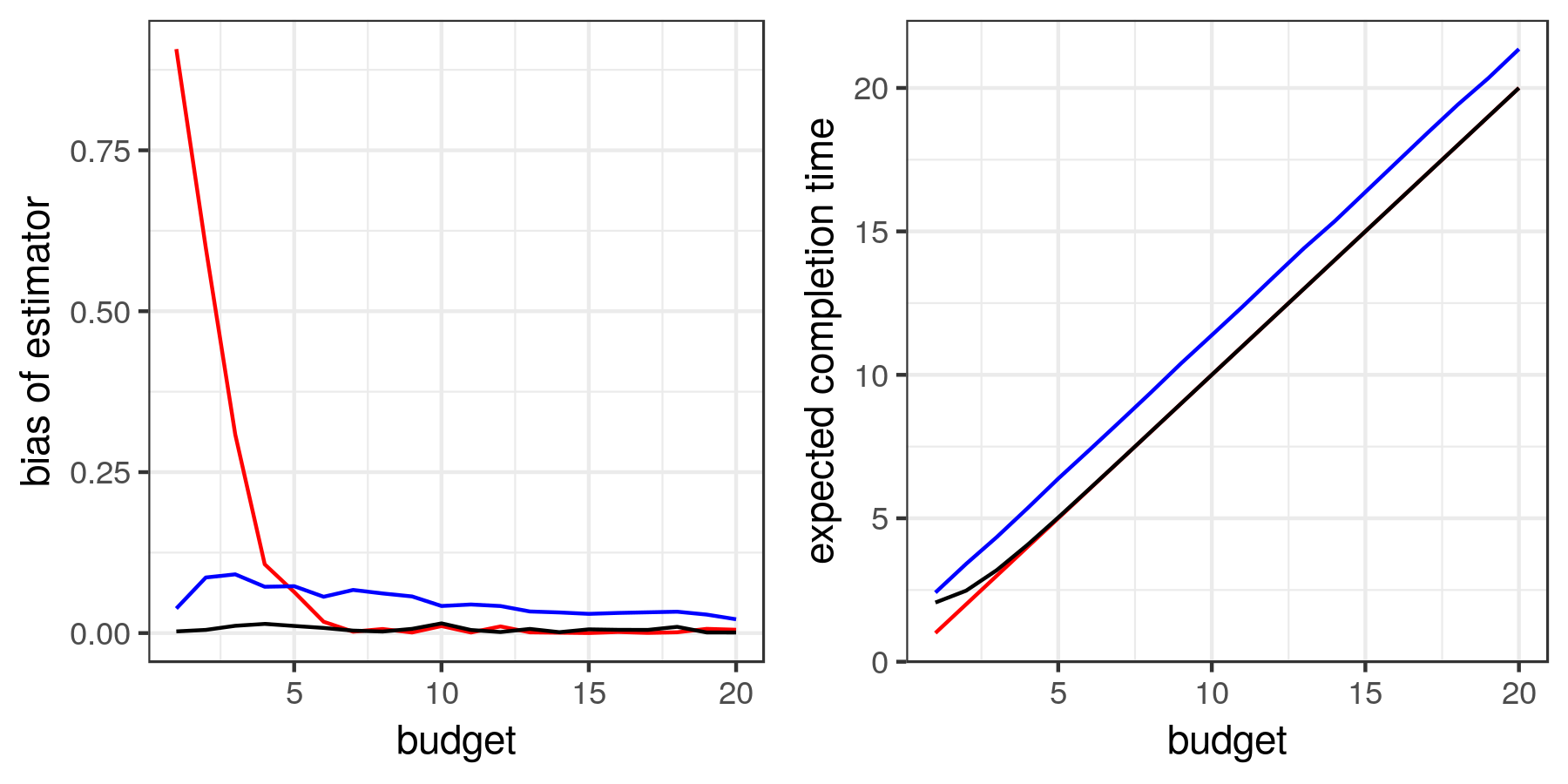
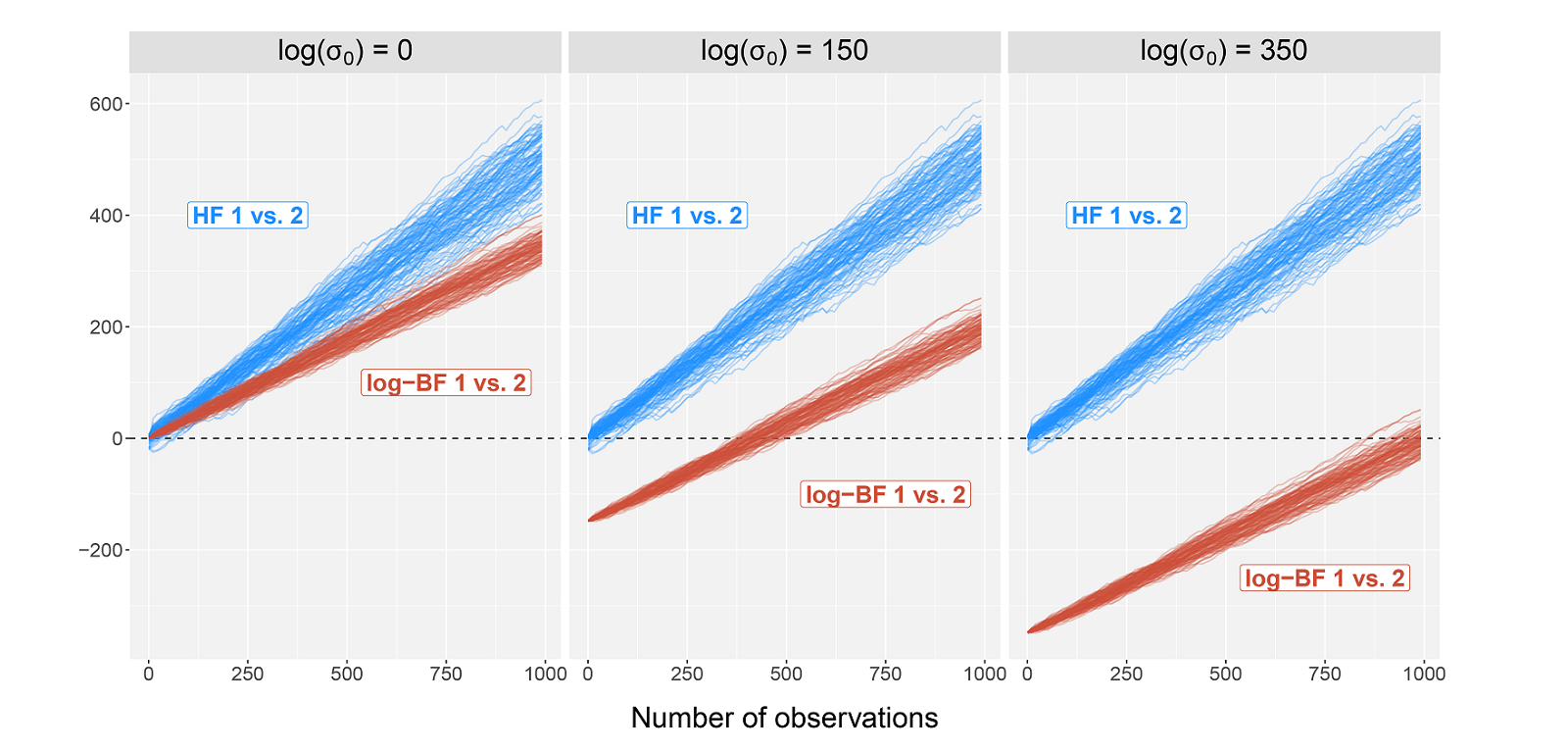
Chapter 2. Approximate Bayesian Inference. This chapter is concerned in large parts with computational aspects of Bayesian inference. It describes: (i) conditional approaches in the form of truncation-based approximations for the Pitman–Yor process and for completely random measures, (ii) a marginal approach based on approximations of the predictive distribution of Gibbs-type processes, (iii) an approximate Bayesian computation (ABC) algorithm using the energy distance as data discrepancy.
Chapter 3. Distributional Properties of Statistical and Machine Learning Models. This chapter is concerned with general distributional properties of statistical and machine learning models, including (i) sub-Gaussian and sub-Weibull properties, (ii) a prior analysis of Bayesian neural networks and (iii) theoretical properties of asymmetric copulas.Continue reading “French Habilitation: Bayesian statistical learning and applications”


 which shows, for two parameters of the model, the cumulative distribution function (CDF) under standard Bayes (blue thin line) and under BayesBag (wider red line). BayesBag results in distributions on the parameter space that are more “spread out” than standard Bayes.
which shows, for two parameters of the model, the cumulative distribution function (CDF) under standard Bayes (blue thin line) and under BayesBag (wider red line). BayesBag results in distributions on the parameter space that are more “spread out” than standard Bayes.